

Taking a page from software development
There's a shift happening in the data industry. Those who write SQL models want to be the ones who ship and productionize that code. Why? Because relying on another team to do it is too damn broken. Too often a data analyst is not empowered to create clean data tables in the company data warehouse herself, despite the fact that it is a necessary first step to any analysis. As a wise man once wrote, "an analytics engineer is really just a pissed off data analyst".
The DevOps movement was born out of that frustration. Tired of the organizational disconnect between developers and IT operations, software teams decided to change how they worked to have more continuous ownership of the code. Developers got really good at not only building features, but also integrating new code, testing, shipping, and supporting it. Companies that embraced this agile way of working, shipped more frequently and benefited greatly.
dbt is not just software. It's a movement towards a new way of working with data. And dbt Cloud provides the tools to empower analytics engineers to own the full end to end development and deployment process.
If you're new to thinking about version control, testing, environments, and CI/CD, and how they all fit together, then this post is for you. We'll walk through how to set up your dbt Cloud project to best match your workflow and desired outcomes.
Continuous delivery vs. continuous deployment
Let's start with some basics.
What is CI/CD? CI stands for continuous integration, which is the process of ensuring new code integrates with the larger code base. CD stands for either continuous delivery or deployment; they aren't interchangeable -- you need to decide which will better support your team's priorities.
With continuous deployment, once code has passed all pipeline CI checks, it will automatically be pushed to production. With continuous delivery, approved code gets shipped to production in batches according to a chosen release cadence.
At dbt Labs, we use data to drive decisions, and while we do have a dedicated (and may I add, fantastic) data team, we're all empowered to make transformations in our dbt repo that enable us to work smarter. That's the power of dbt; it allows people with the business context to make the change.
About 25% of our employees, across all functions, have contributed to our dbt internal analytics codebase. We don't want to wait all week to see our changes go live, as we need the data more immediately to inform our decisions. Speed and a decentralized workflow suit our team, and we've adopted a continuous deployment process so we can ship new code whenever it's ready and tested.
The two options have their tradeoffs though.
Continuous deployment provides a more automated process for shipping new data models. However, with any process that allows teams to move quickly, there's an increased risk of errors.
Continuous delivery creates a batched process through which code gets released on either a temporal or project-based cadence. This process has a few more speed bumps to ensure code has been thoroughly tested before making it to production, and it is a great choice for teams who have a very high bar for data reporting.
Option 1: Setting up continuous deployment with dbt Cloud
With continuous deployment, you only need to use two environments: development and production, and dbt Slim CI will create a quasi-staging environment for automated CI checks.
The development environment is where each developer has her own workspace, under a dedicated schema, to create, update, and test dbt models while working in the dbt Cloud IDE.
When a developer wants to create a new model or make a cohesive set of code changes, she checks out a descriptively named feature branch (ex. feature/orders-model-update). After the analytics engineer commits her cohesive set of changes, she opens a pull request.
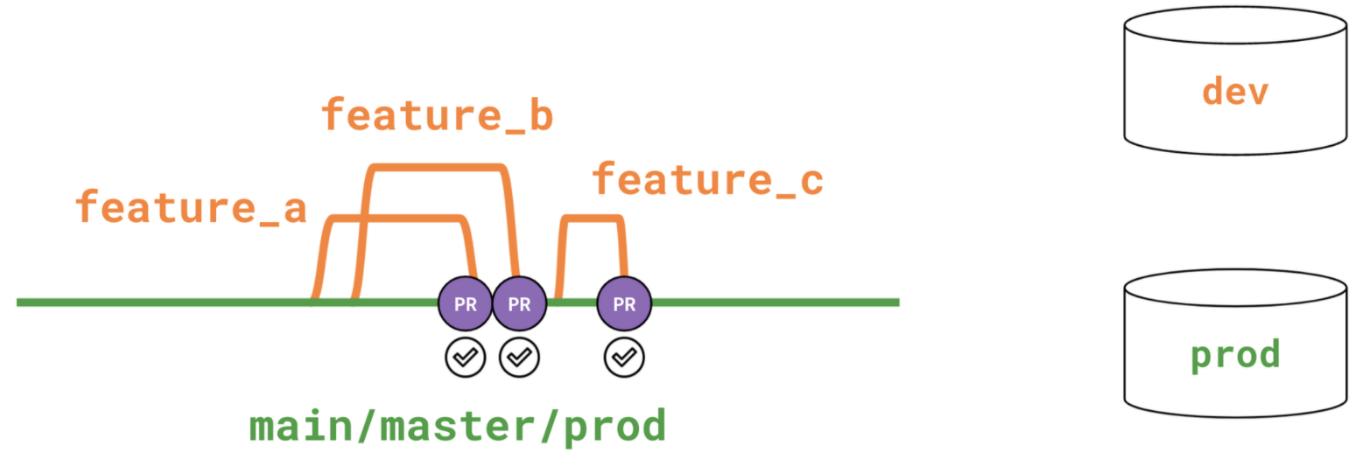
A best practice is to run CI checks on every pull request, which dbt Cloud enables via Slim CI jobs.
A Slim CI job is a job that gets triggered via webhook or API on PRs. You can set the job to defer to a different production job that builds the project's full DAG. This way, the CI job builds and tests only models that are new or modified since the last production run. Importantly, these models will build into a temporary PR schema, so that the reviewer can inspect model relations before approving the PR. dbt Cloud will require this CI check on every PR made in the dbt repo, giving users confidence that their new code is building as expected and not introducing errors when it's merged into the main branch.

The temporary PR schema will drop whenever the PR is closed or merged so as not to create clutter in the warehouse.
The production environment is set up to run jobs on a schedule and builds the code off the main branch in the dbt repo.
This two-environment design ensures good process, while also allowing for development and deployment speed.
Option 2: Setting up continuous delivery with dbt Cloud
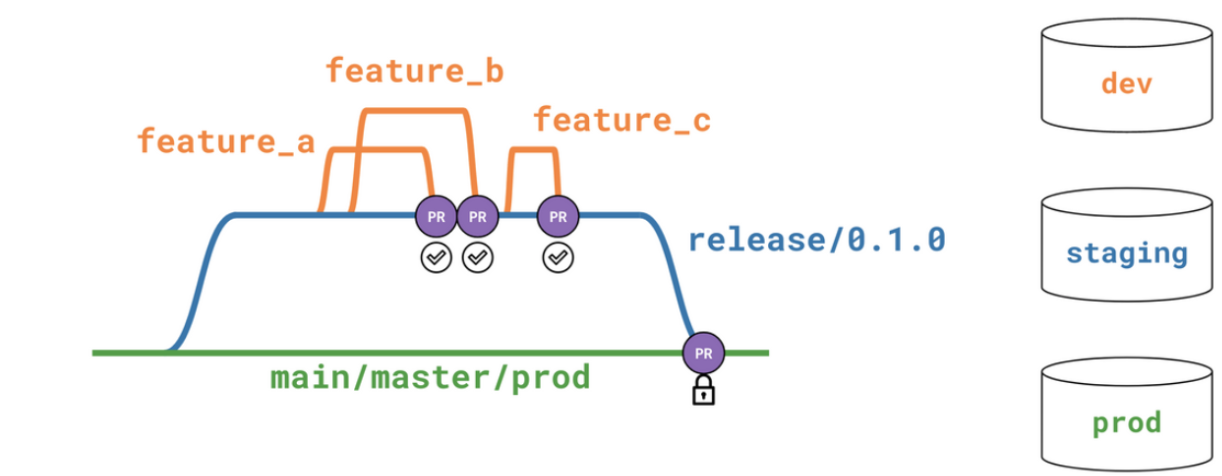
This process uses the trifecta set up of separate development, staging, and production environments, and it is usually coupled with a release management workflow. Here's how it works:
To kick off a batch of new development work, a Release Manager opens up a new branch in git to map to this release's work (ex. branch release/0.1.0).
Just as described in Option 1, the developer checks out a feature branch in the IDE to begin her work. However in this set up, feature branches merge into the release branch rather than the main branch.
To enable this workflow, turn the custom branch setting to 'ON' in the development environment, and set the branch to the release branch name as shown here:
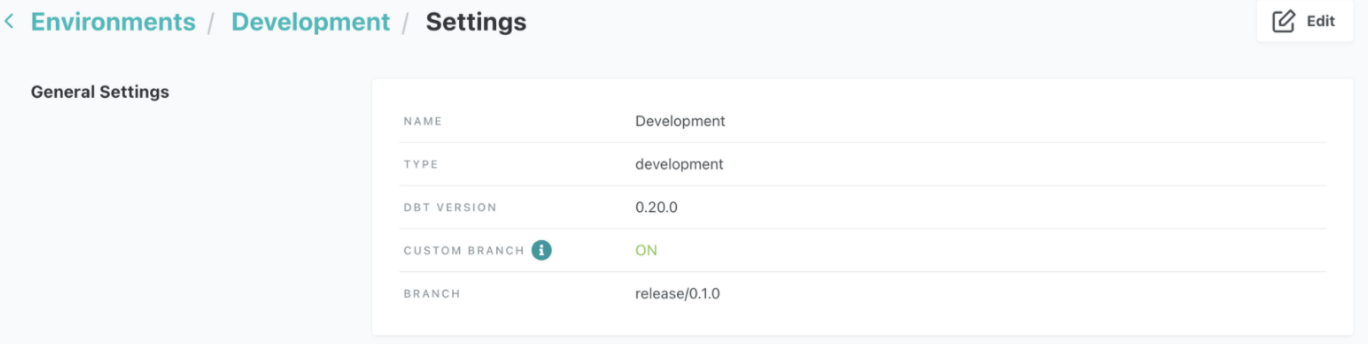
A custom branch set in a development environment tells dbt Cloud which destination branch you want to merge your feature branches into; whereas, a custom branch set in a deployment environment tells dbt which branch's code should be used to build models.
Teams may decide to release every week; which means that all week long analytics engineers check out feature branches, commit new code, run Slim CI checks on their new models, and merge their feature branches into the release branch.
At the end of the week, or specified release period, the Release Manager will try to merge the release branch, containing all the newly merged feature PRs, into the main branch by opening up a PR in git. A Slim CI job in the staging environment runs the up-to-date release branch code to ensure that the models work together without any surprises. This job can similarly defer to a production job that runs the full DAG, so that you don't waste resources by rebuilding models unaffected in this release. If all the models in the release build together as expected and all the tests pass in the Staging CI job, the Release Manager can merge the release branch into the main branch.
Note that there are two levels of testing that happen in this release process. The first set of tests happen before each feature branch is merged, and the second test is an integration test, checking that all the new features work together.
The production environment's jobs all run off the main branch, which has been thoroughly vetted, and the whole development workflow starts over when the Release Manager opens the next release branch, release/0.1.1.
Below is a diagram summarizing the three environment set up.
Releases are often accompanied by documentation in a Changelog, which updates stakeholders about changes to models. As a result of the release, dashboards or other downstream consumers of dbt tables often need to be updated. dbt Exposures can help teams describe dependencies and share context for how data is ultimately consumed.
While this process adds some friction to the workflow, the speed bumps hopefully ensure high code quality.
And now you're working smarter
Whether you choose a continuous deployment or continuous delivery workflow for your team is a preference based on culture and risk tolerance. What matters more is that your team has taken a massive leap forward in creating and deploying reliable analytics code that helps your business move faster. With some support from dbt Cloud, the same team responsible for writing the code can also deploy it.
Last modified on: Feb 27, 2024

Achieve a 194% ROI with dbt Cloud. Access the Total Economic Impact™️ study to learn how. Download now ›