dbt and Hightouch are putting your transformed data to work

Jul 27, 2021
Partnerships
A thriving ecosystem requires interoperability across different layers of the data stack. This interoperability is made possible only by the existence of standards.
As a sign of dbt increasingly becoming the standard for modern data transformation, Hightouch now officially integrates natively with dbt to help you bring "Reverse ETL" to your stack.
Hold on to your socks: I'll walk you through this.
What even is Reverse ETL?
The short version is: Reverse ETL is the process by which transformed data is fed from your cloud warehouse back into your operational tools. This lets your business teams access your data in the tools they use every day for things like marketing, sales, and customer support.
But let's back up a bit.
Your business generates a lot of data. That's probably why you're here. There's clickstream data, ad performance data, transaction data, and a whole bunch more.
While your data is generated from a bunch of different sources, chances are, if you're invested in a modern data stack, the center of gravity for your data is the cloud warehouse. That's where it all lives. It probably got there via an ETL / ELT tool like Fivetran, Airbyte, or Stitch.
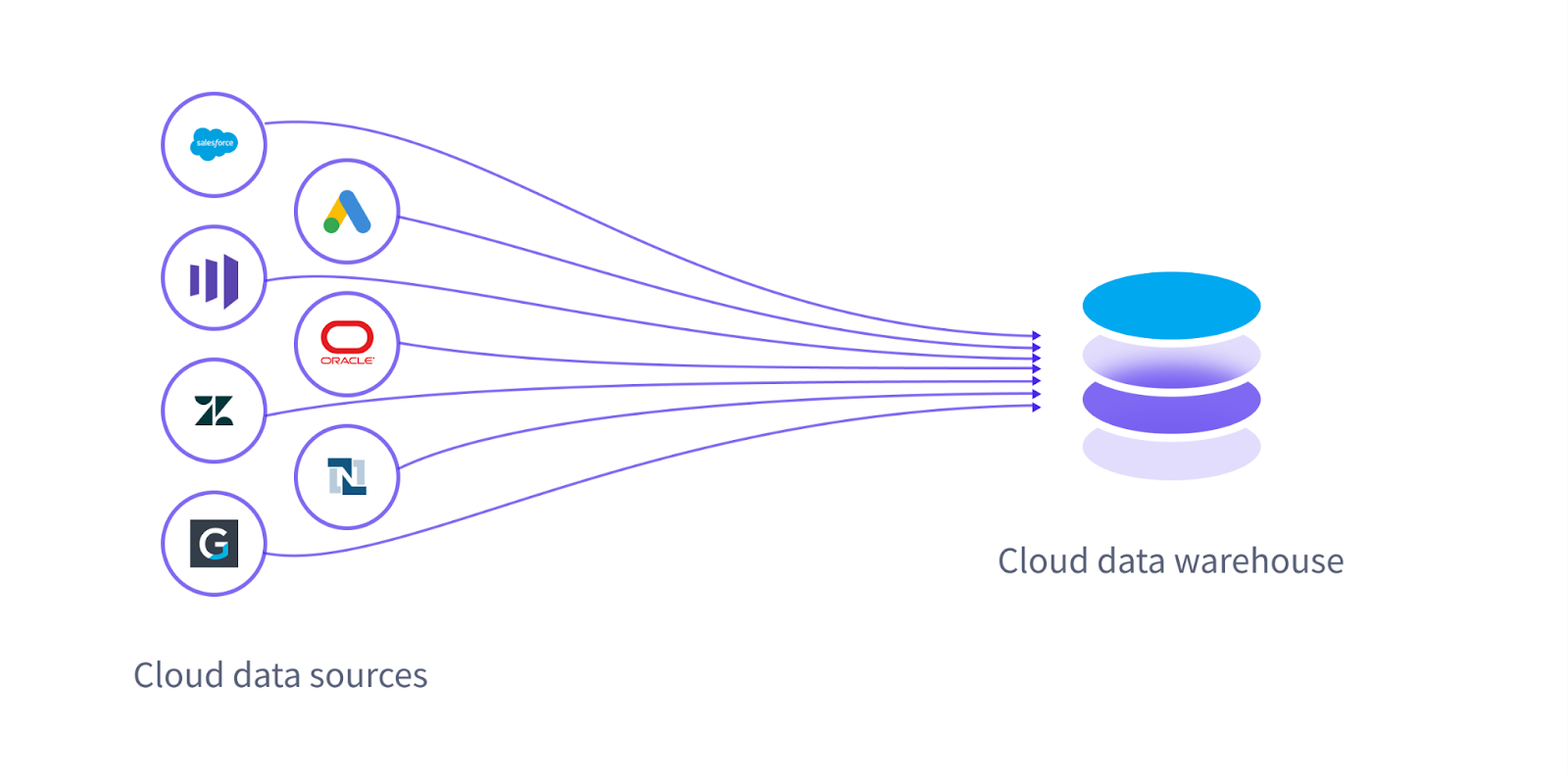
Inside your data warehouse, you're likely modeling your data using dbt, because of course you are.
So why is this not ideal?
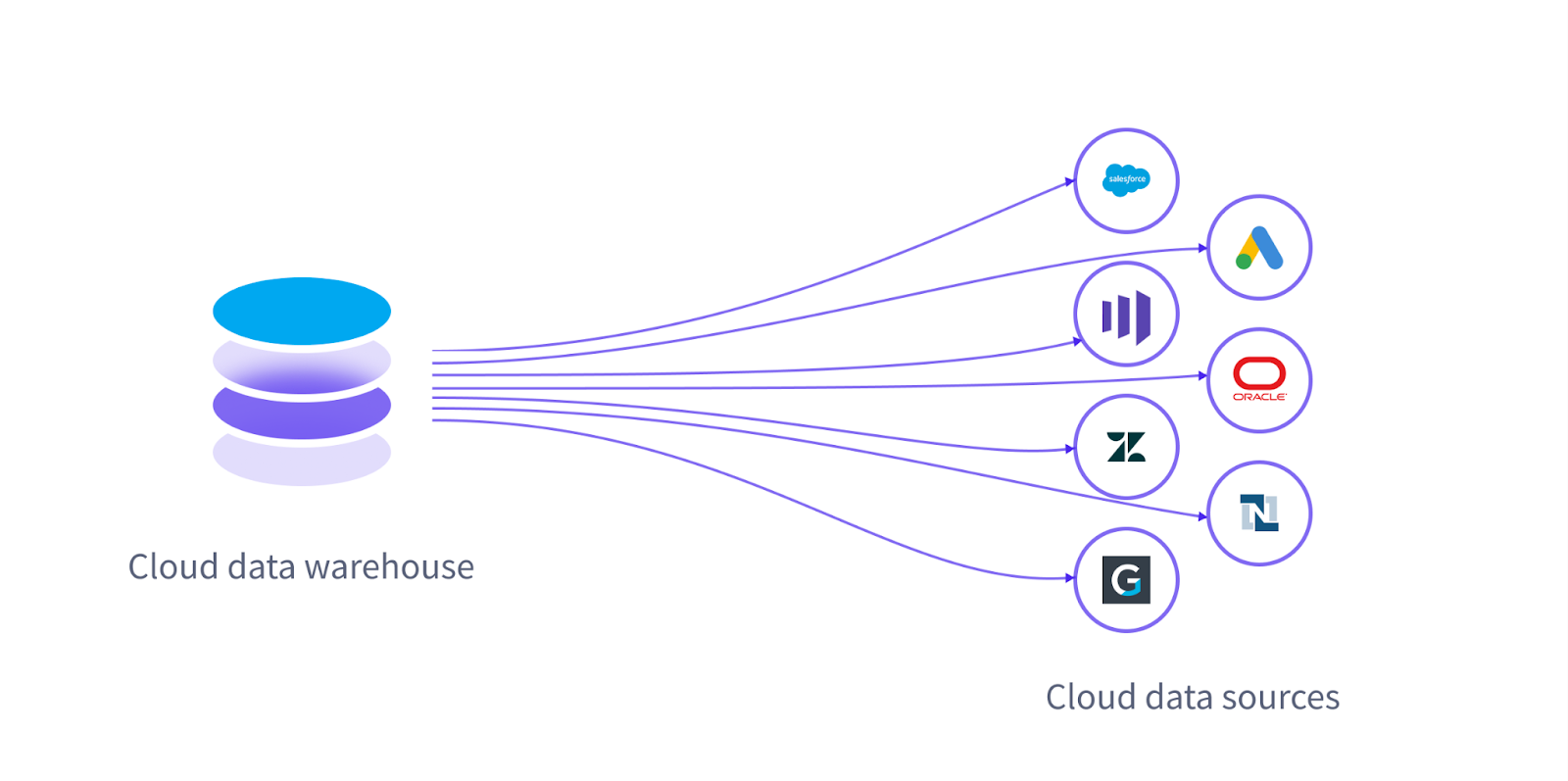
Reverse ETL is helpful because your data warehouse --- the platform you bought to eliminate data silos --- has ironically become a data silo. Without reverse ETL, your business's core definitions only live in the warehouse.
Sure, you can easily create dashboards using this data in BI tools, but these insights are much more powerful if data consumers can navigate them in the tools they are already using every day.
Getting your data into their favorite tools means fewer tools to learn, fewer mistakes, less friction, faster time to value from your data, and just generally more stakeholder delight.
dbt + Hightouch
Hightouch now integrates natively with dbt, allowing you to pull your existing dbt models via git and send modeled data from your warehouse to over 60 different tools. Combined, dbt and Hightouch bridge the gap between data and business teams to enable everyone to use modeled data however they need.
(Yes, even you, Bob. You're welcome, Bob.)
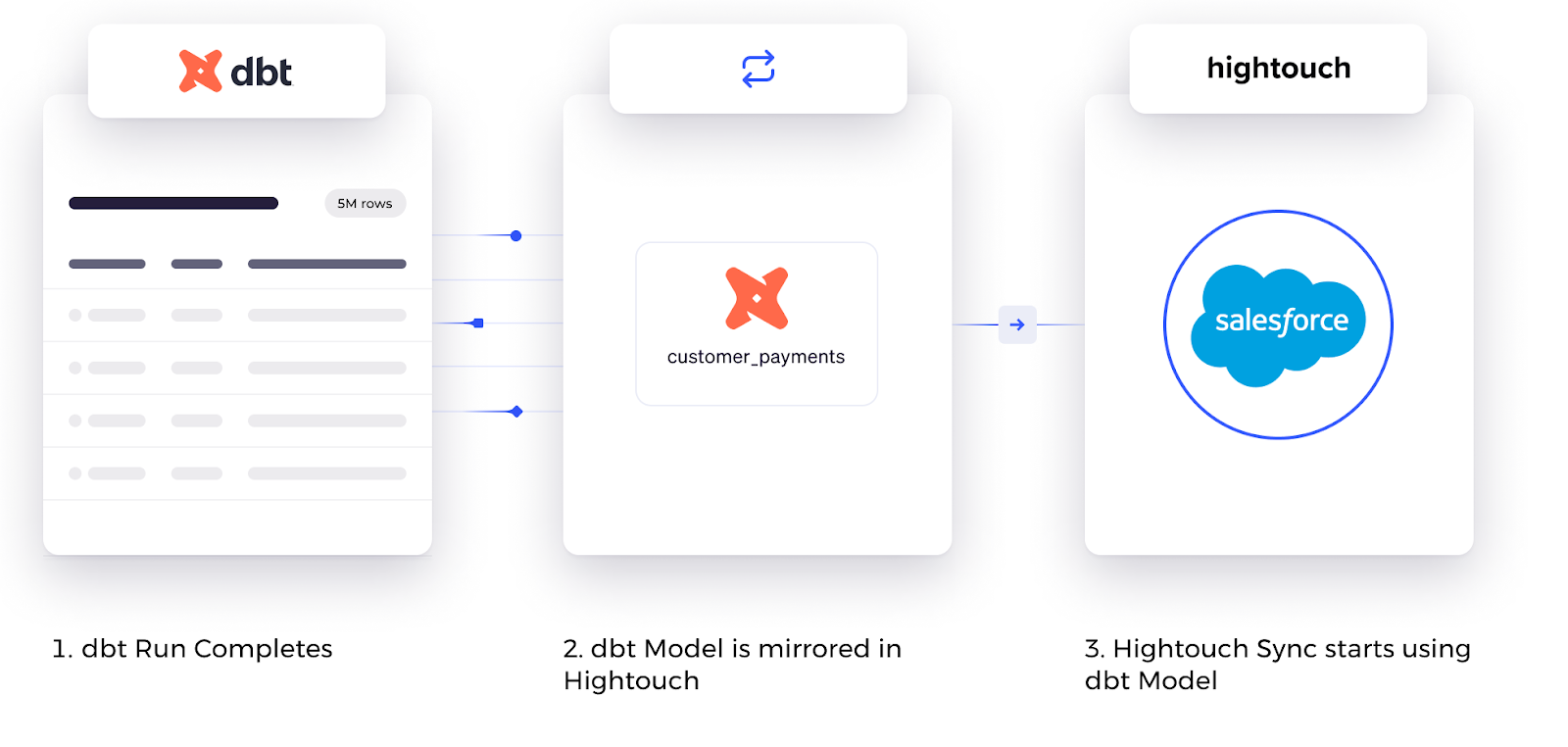
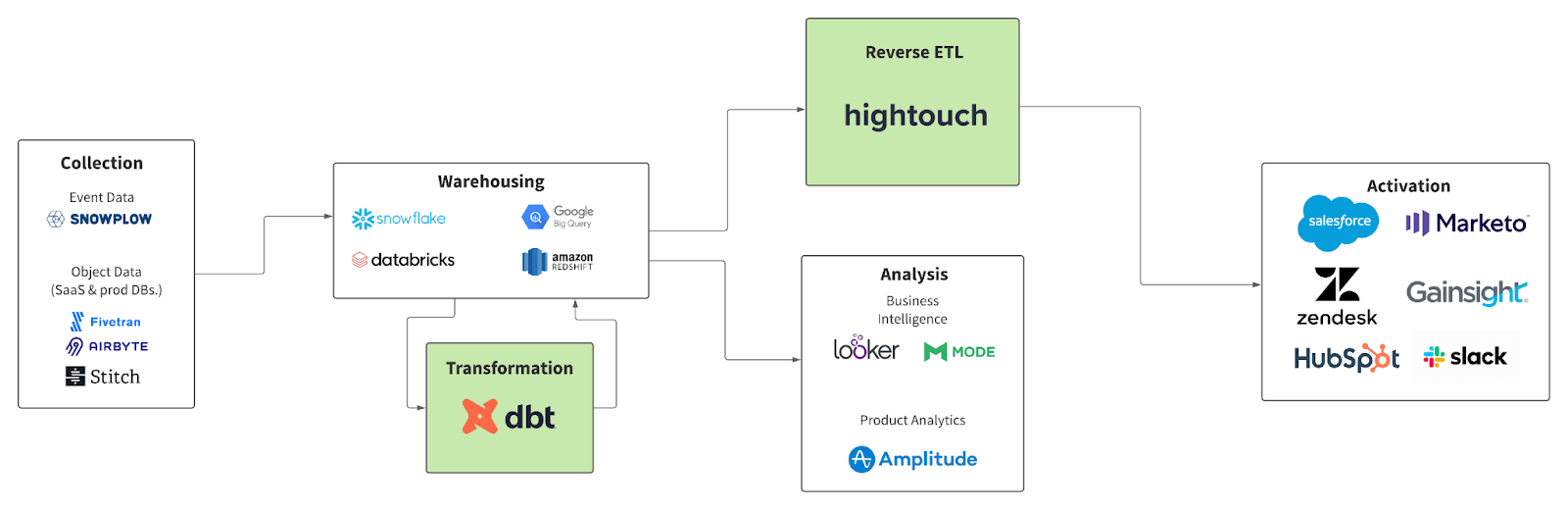
With dbt's collaboration, deployment, and testing functionality, you can create robust models that drive business value such as propensity scores, lead scores, customer health scores, ARR/MRR, funnel stages, and more. Then, by simply triggering a Hightouch sync after your dbt Cloud job, you can send modeled data to:
- CRM systems such as Salesforce, Hubspot, and Pipedrive to better understand customer acquisition;
- Marketing automation platforms such as Pardot, Marketo, and Omnisend to deliver personalized marketing campaigns;
- Customer Support and Success Helpdesk solutions like Zendesk, Gainsight, and Totango to pre-emptively identify and reduce churn;
- Workflow tools like Slack and Asana to automate internal ops processes
You might already be doing some of this in-house using a complex web of scripts and API calls, but a tool like Hightouch takes out all the tedious work, freeing up your data engineering resources to focus on the infrastructure work where they add the most value.
William Tsu on Blend's Customer Success Operations team had this to say:
"We use dbt to model data from various sources in our warehouse. Specifically, dbt allows us to codify and version control all the business logic that determines our company's key metrics (eg: Annual Run Rate, Customer Counts, Feature Adoption, etc.). Hightouch is then used to pipe this data out to the relevant stakeholders. This makes sure that everyone at Blend is using the same methodology when it comes to analytics."
Putting your data to work
Here's what you can do today with Hightouch's native integration with dbt Cloud:
- Schedule Syncs after dbt Cloud jobs: You can now put your data into action as soon as it's been modeled by scheduling a Sync to execute after your dbt Cloud job runs. This ensures that Hightouch always performs Syncs with fresh data. All you need to do is connect your account using the dbt Cloud API, and select the job you want a Sync to run after.
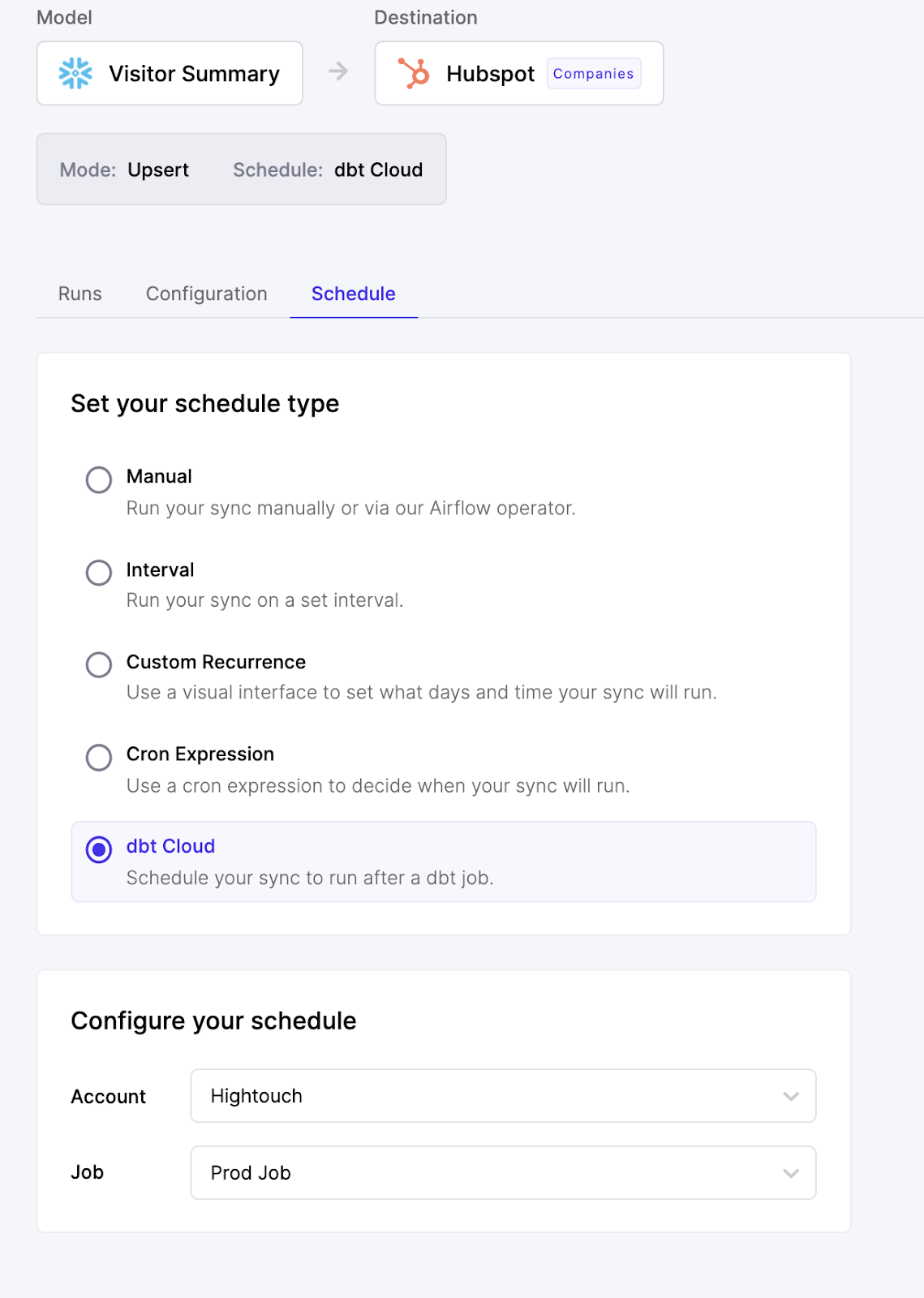
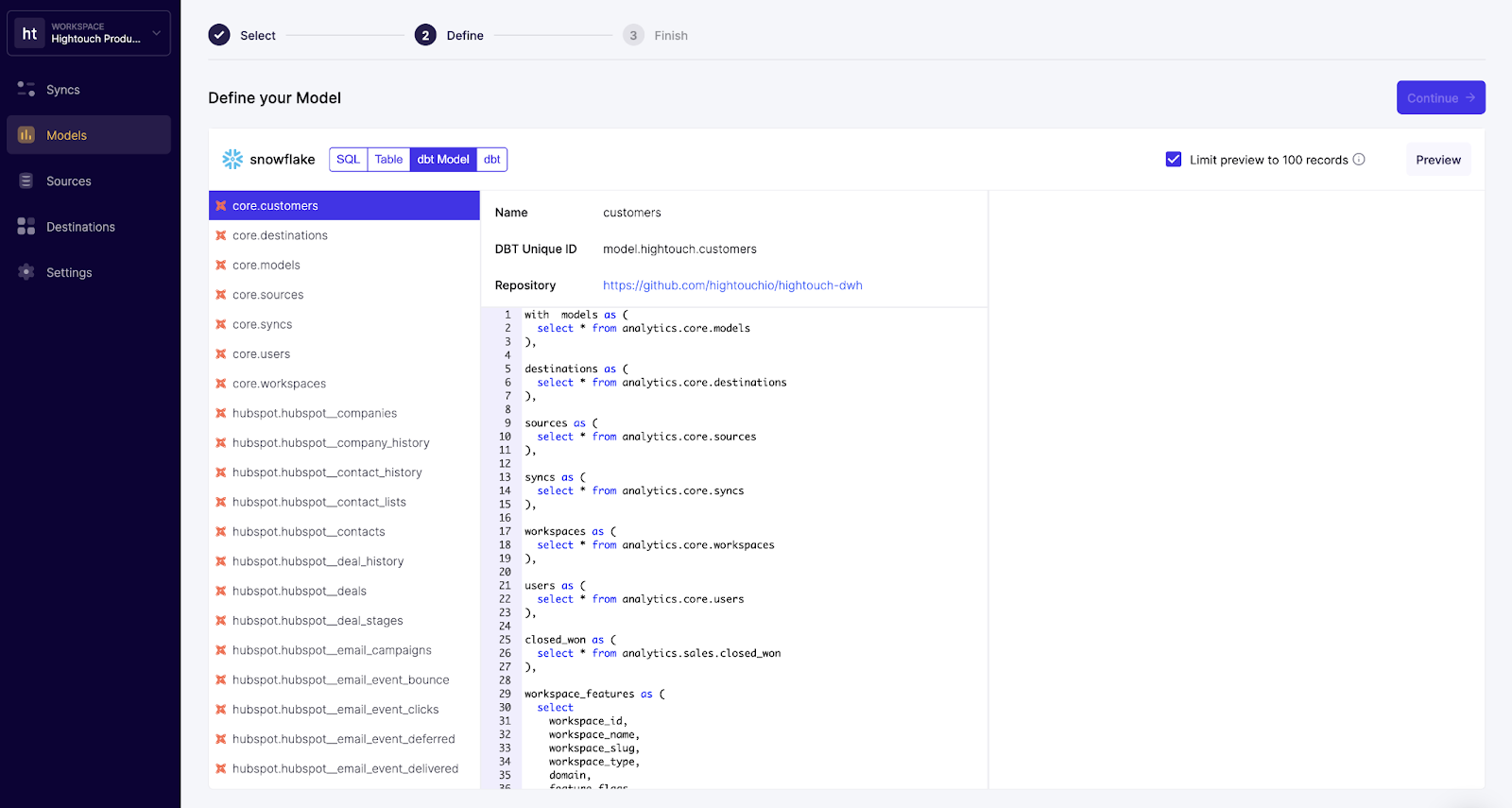
- Select dbt models to sync, version controlled through git. Hightouch's dbt Model Selector allows you to pull your existing dbt models via git and send data to over 60 destinations. That way, whenever you update your dbt models, Hightouch automatically reflects those changes in your Syncs.
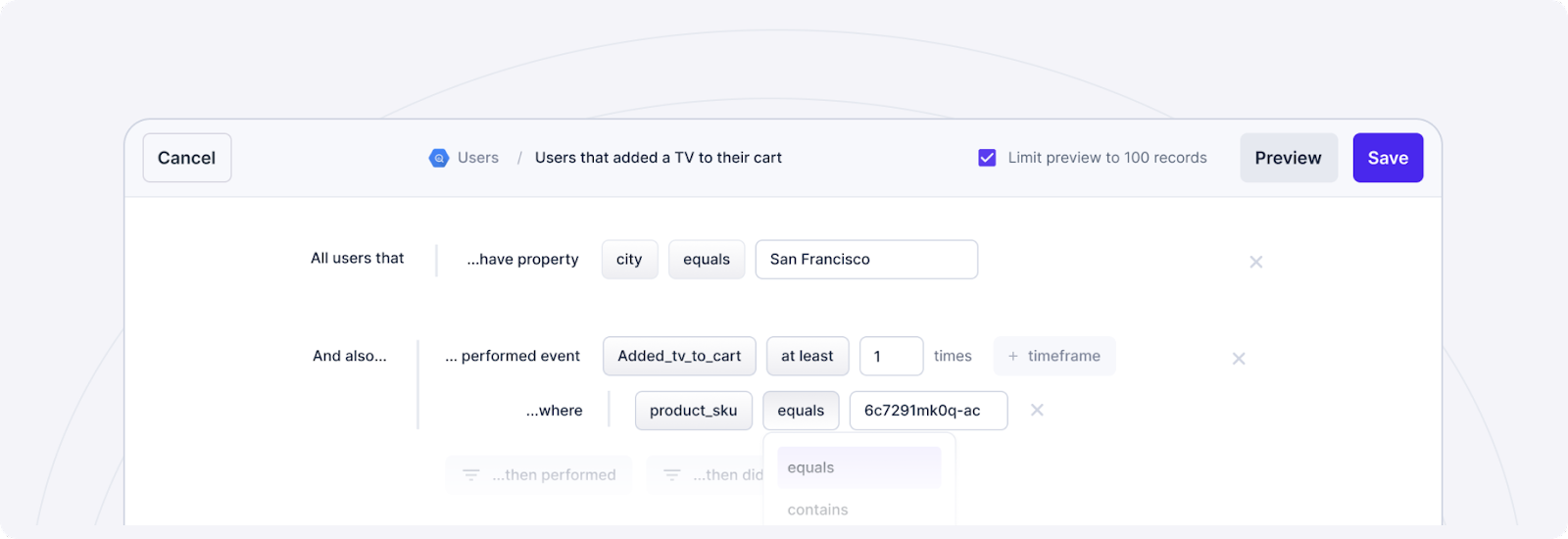
- Visually filter modeled data through an easy-to-use UI. This provides a clear hand-off between data and business teams. Data teams own the modeling of data (using tools like dbt) and then business teams own how that modeled data should appear in their tools. The crux? This means that business teams can now ✨ self-serve ✨ data pipelines into their own tools.
And if you'd prefer to watch this in action instead of read about it, then fret not. You're in good hands:
The future of dbt and Hightouch
Our friends over at Hightouch are pretty committed to the idea that data teams and business teams should be able to do everything in the tools they are most comfortable with. While today you can trigger Syncs after dbt Cloud jobs from within Hightouch, in the near future, they want to allow teams to create entire Hightouch Syncs within dbt Cloud itself.
In fact, Hightouch just moved one step closer to this dream by enabling users to configure Syncs through creating or editing JSON objects directly (which will be doable through dbt Cloud or the dbt CLI soon).
Getting started with dbt + Hightouch
If you're interested in getting your Reverse ETL on with dbt and Hightouch, check out the Hightouch website and docs to get started today. And if, along the way, you need a little help or just want a place to share your excitement, don't forget to chime in on #tools-hightouch or #operational-analytics on Slack.
It's time to set your data free. After all, how would you like to be stuck in a warehouse all day?
Last modified on: Feb 27, 2024

Achieve a 194% ROI with dbt Cloud. Access the Total Economic Impact™️ study to learn how. Download now ›