

You need to figure out how to deal with that nasty JSON array living in the varchar(max) field you're staring at.
You've come to the right place.
Redshift's lack of an unnest, or flatten, function is a little frustrating given that Amazon's other columnar SQL products, Athena and Spectrum, both have the ability to deal with arrays natively. Why no love for Redshift?
Enough griping. Let's write some SQL.
Setting up the environment
Imagine we have an ecommerce database where the orders table, with one record per order, contains a nested array of items: the individual products purchased in a given order. Here's the setup data so that you can run it yourself:
create table dbt_jthandy.flatten_test (
order_id int,
json_text varchar(1000)
)
;
insert into dbt_jthandy.flatten_test
(order_id, json_text)
values
(1, '{
"items":[
{
"id":"fa4b6cd3-4719-4b97-848b-7f2025f5e693",
"quantity":1,
"sku":"M900353-SWB-RYL-2",
"list_price":60.0
},
{
"id":"c39f9474-a278-4162-9cfa-aa068f4e1665",
"quantity":1,
"sku":"F033199-SWB-FWL-1",
"list_price":20.0
}
]}')
;
insert into dbt_jthandy.flatten_test
(order_id, json_text)
values
(2, '{
"items":[
{
"id":"fa4b6cd3-4719-4b97-848b-7f2025f5e693",
"quantity":1,
"sku":"M900353-SWB-RYL-2",
"list_price":60.0
}
]}')
;Simple, right? Plenty for what we need to do. Let's see what we can do with it.
The easy stuff
Here's something that's easy to do: grab the contents of the items array out of the JSON object:
select
order_id,
json_extract_path_text(json_text, 'items', true ) as items
from flatten_testThis uses one of Redshift's core JSON functions, json_extract_path_text. Look at the docs, they're good. Here's your result:

It's hard to see in the narrow table above, but order_id = 1 actually contains the entire JSON array with two nested objects.
So far we've just pulled out a single item of the object, items. What else can we do? Let's try grabbing the first item out of the array:
select
order_id,
json_extract_array_element_text(
json_extract_path_text(json_text, 'items', true ),
0, true )
from flatten_test
We've added a json_extract_array_element_text (docs) call on top of the previous query to get the first element of the array (which is zero-indexed). This returns the following table:

This time we only get back the first element of the order_id = 1 record.
Finally, we're able to get the total number of array items in the items array:
select
order_id,
json_array_length(
json_extract_path_text(json_text, 'items', true )
, true) as number_of_items
from flatten_testThis uses another critical Redshift JSON-parsing tool, json_array_length (docs). That query returns this rather humble result:
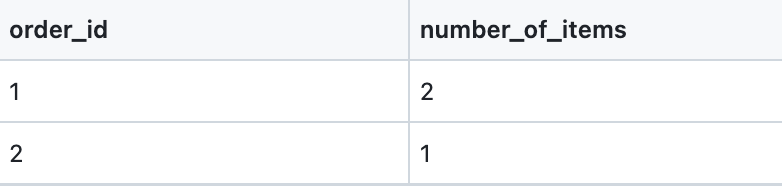
Ok all of this is great. We've been able to grab a specific key out of an object, we've been able to grab a particular item out of an array, and we've been able to count the items in an array, and it's all been pretty easy (if a bit verbose!). But we haven't actually flattened the table. It turns out, that's rather harder.
Putting it all together: pulling off the unnest
In order to actually execute our unnest, we're going to have to fan out the number of rows in the source data: we don't want one record per order, we want one record per item. In order to get there we'll cross join against a numbers table.
Generating a numbers table is a whole topic unto itself. While Redshift does now have a generate_series function, that function doesn't seem to allow its outputs to be used by other downstream SQL functions, and the results can't be saved into a table either. If you're using dbt to write this SQL (which I highly recommend), you can use the dbt-utils generate_series() macro to build yourself numbers table. If you're not using dbt, I leave it as an exercise for the reader to create a table called numbers with a single column called ordinal. It should have 10 rows; the numbers 0 to 9.
Once we have our numbers table, we need to cross join to it and then parse out the results. Here's the entire SQL:
with orders as (
select
order_id,
json_extract_path_text(json_text, 'items', true ) as items
from flatten_test
),
numbers as (
select * from numbers
),
joined as (
select
orders.order_id,
json_array_length(orders.items, true) as number_of_items,
json_extract_array_element_text(
orders.items,
numbers.ordinal::int,
true
) as item
from orders
cross join numbers
--only generate the number of records in the cross join that corresponds
--to the number of items in the order
where numbers.ordinal <
json_array_length(orders.items, true)
),
parsed as (
--before returning the results, actually pull the relevant keys out of the
--nested objects to present the data as a SQL-native table.
--make sure to add types for all non-VARCHAR fields.
select
order_id,
json_extract_path_text(item, 'id') as item_id,
json_extract_path_text(item, 'quantity')::int as quantity,
json_extract_path_text(item, 'sku') as sku,
json_extract_path_text(item, 'list_price')::numeric as list_price
from joined
)
select * from parsedAnd here's the resulting table:

Clean, right?
Final thoughts
Writing this same SQL on Snowflake or Bigquery feels idiomatic: you simply use the flatten function on Snowflake (docs) or the unnest function on Bigquery (docs). Both platforms support this type of nested data in a first-class way, and it significantly improves the experience of data analysts. I hope to see Redshift improve this functionality in the future.
If you are on Redshift, you should prefer ingestion processes that automatically normalize any JSON data that they run into for Redshift destinations (we're fans of Stitch and Fivetran). But if you do find yourself with a JSON array to deal with on Redshift, this is a very solvable problem.
Once you've transformed your raw array into a clean dataset, make sure you save that result as a table or view back into your database using dbt. You don't want your fellow analysts to go through the same headache that you did, right?
⚡️Ready to improve your analytics engineering workflow? Get started with dbt today. ⚡️
Last modified on: Mar 25, 2024

Achieve a 194% ROI with dbt Cloud. Access the Total Economic Impact™️ study to learn how. Download now ›