Introducing Environment Variables in dbt Cloud

Oct 26, 2021
Product News
Scaling up your dbt project
You have the basics down of developing a dbt project. That's awesome! Now it's time to think about how to productionize your project to run dependably in deployment environments. When you have the same dbt repo code running in 3 places (dev, staging, and prod), you may find yourself itching to change the behavior of dbt depending on the context.
To try and work around this, we've seen folks pass around dictionaries of variables in job commands or create complex conditional logic relying on target.name . Not ideal! What you really want is environment-aware code. Starting today, you have it. Environment variables are now supported in dbt Cloud.
What are environment variables?
Environment variables are related to the variables you know today, but a little different. Their value is set outside the program and is static and available to the code in a particular context.
You can reference them in your dbt project by calling the Jinja function {{env_var('DBT_KEY', 'OPTIONAL_DEFAULT')}}. The environment variable is then interpreted depending on where dbt is run. A job that runs in a Staging or a Production environment can now recognize where it's running, and dbt Cloud sets the value accordingly.
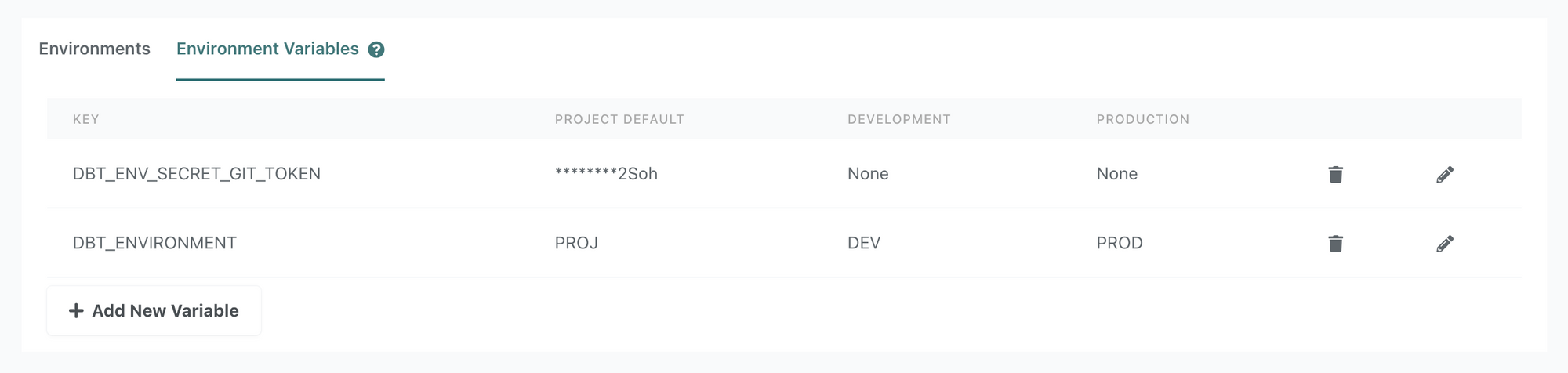
Environment variables give you the power and flexibility to do what you want, more easily.
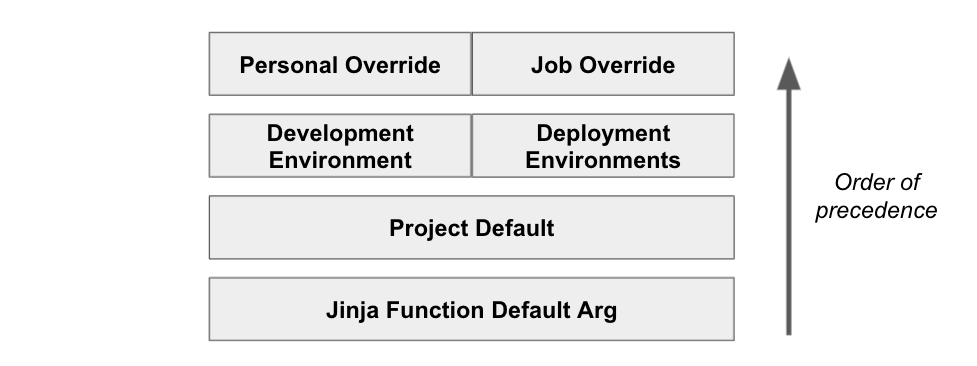
There are four levels of environment variables:
- The optional default argument in Jinja,
- a project-wide default value, which can be overridden at
- the environment level, which can in turn be overridden again at
- the job level or in the IDE for an individual dev.
With this level of granular control, you can solution most problems that your team might come up with.
Let's explore some examples:
Cloning private packages
You have a private package that you need to clone at the start of a run. You'll need a git token to authenticate the repo clone. You can now store the token in an environment variable secret that dbt will access at runtime. See docs for details.
Limiting the amount of data that is processed in development environments
In production, you'll need to materialize the full table, but when in dev, you might want to materialize a subset of the data for faster processing. You can create conditional logic based on the environment to pull data from a smaller window of time.
Changing your data sources, depending on the environment
Perhaps in dev, your sources change altogether to point to a schema with test data tables. You can set your schema to be an environment variable, ex {{env_var('DBT_STRIPE')}}, and then the value will point to a different collection of data tables depending on the environment.
Overriding a Snowflake virtual warehouse for a specific dbt Cloud job
You want to dynamically change the Snowflake virtual warehouse size depending on the job. Instead of calling the warehouse name directly in the connection, you can reference an environment variable which will get set to a specific virtual warehouse at runtime. See docs for details.
Write Once, Run Anywhere
Environment variables create a way to separate code from configuration - allowing you to set config based on context and keep secrets like git tokens securely stored. This new feature adds another dimension to projects running in dbt Cloud, and we're excited to hear about all the ways you put it to work! Seriously, let me know --- @julia_schottenstein in the dbt Community Slack.
Last modified on: Mar 05, 2024

Achieve a 194% ROI with dbt Cloud. Access the Total Economic Impact™️ study to learn how. Download now ›