
dbt is built on two different topological structures: the hierarchy and the graph.
- dbt models are stored on disk and referenced in configuration in an infinitely-nested hierarchy.
- Models reference one another (via
ref()) and create a directed acyclic graph of computation.
This two-topology world has existed since the very beginning! Drew and I were very intentional about designing this into the foundations of dbt and found that the hierarchy and the graph interacted with each other in really useful ways.
The DAG
The utility of the DAG speaks for itself; the DAG is the central construct in modern data engineering and dbt wouldn't be very useful without it. Try building a dbt project without the ref() function!
The Hierarchy
The hierarchical topology is less important but still key to the utility of dbt. Having this layer on top of the DAG has always given users a ton of flexibility in how they structure their projects. Hierarchy drives all types of configuration, so it's common to do things like set a materialization strategy for all models in a certain directory (for instance...materializing all staging models as tables). It also enables a lightweight way to create "interfaces" to different sections of a dbt project---defining areas such as staging and marts (for example) that have different SLAs and development practices associated with them. Over the years, users have used the hierarchical structure of their dbt projects to express all kinds of useful constructs.
The Problem
The problem, though, is that these two structures make developing dbt code more difficult. It's likely very easy for you to see the other files in the hierarchy that are peers of the file you're working in...just open up a file tree! All IDEs have file trees of some kind.
But when you're writing dbt code, it's actually quite painstaking to navigate the DAG, and it's likely the DAG that you're primarily concerned with. Tracking down a bug? Want to understand the specific code that created a behavior you're trying to understand better? There are a million reasons that you actually want to traverse dbt's DAG, but doing so today is quite cumbersome while writing code.
In the very early days (pre-dbt Docs), I would often find myself drawing (with a pencil and paper) the graph after navigating through a bunch of files and figuring out the relationships.
After dbt Docs, I now use its graph visualization to understand the relationships between models, and then have to tab back over to my editor and open up the file. The whole process of generating the docs, pulling up the relevant sub-DAG, and navigating back to the correct file in my IDE is a high-friction experience, and many folks simply don't do it. Instead, they cycle back and forth between different models trying to keep the underlying relationships straight in their brains.
This experience---one that forces you to choose either a high-friction UX or high cognitive load---has been a major impediment to the dbt workflow for years. And fixing this is a great example of why we are long-term believers in purpose-built dbt IDEs.
The Solution
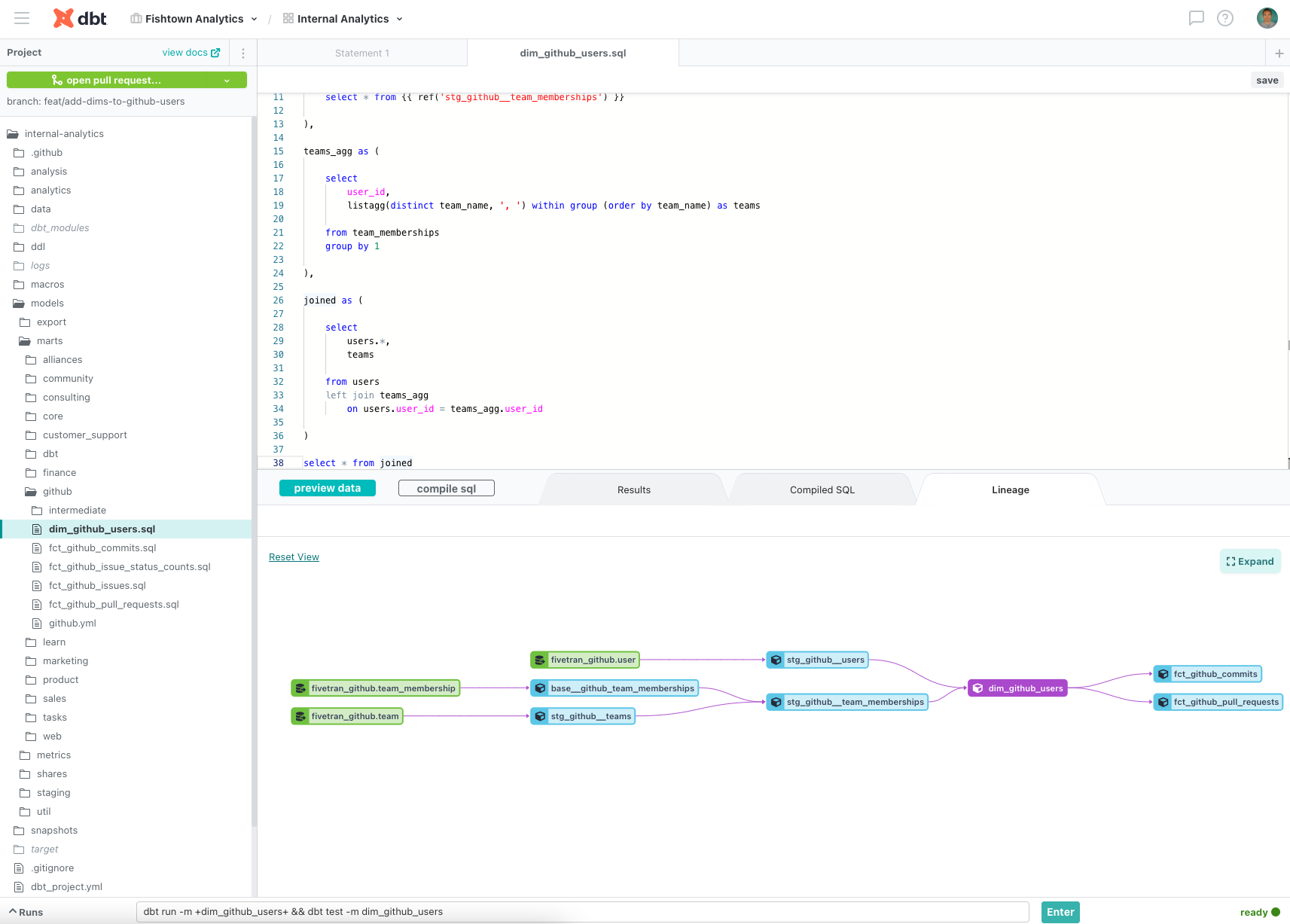
The solution to this problem is conceptually straightforward. If all editors have a native file tree to navigate the hierarchical topology, then dbt editors should also have a DAG explorer to navigate the graph topology! And both the graph and filesystem explorers should allow users to open up models for editing from within that interface.
We've wanted to build this for a long time, and we just shipped it to the dbt Cloud IDE recently.
Check out this video to see it in action:
With the DAG-in-the-IDE, analytics engineers can seamlessly navigate the core structure of their dbt project with low friction and low cognitive load, making the entire development process more intuitive / pleasant / efficient.
This type of IDE functionality is normal for software engineers. Most IDEs have features that enable them to natively operate on the language constructs present in modern software languages. Right click on a function call to go to its definition. Easily factor big chunks of logic out into their own reusable functions. Build diagrams to visualize the flow and structure of code. Highlight syntax issues. Etc.
Very little of this tooling exists for the dbt ecosystem. It should. We have always believed in looking to software engineering practices as a model of where the future is headed, and this presents a pretty clear picture of what the future of a mature dbt IDE could look like. We are excited to continue to push towards this future.
Last modified on: Mar 04, 2024

Achieve a 194% ROI with dbt Cloud. Access the Total Economic Impact™️ study to learn how. Download now ›